
我院在大语言模型交互研究方面取得进展
近日,我院李鹏副研究员及其团队在大语言模型交互研究方面取得进展。针对LLM Agent在复杂动态环境中如何学习并持续提升,团队提出了一种具备策略级自我反思和行为优化的LLM Agent,并在多玩家非完美信息的博弈游戏中进行了实验。成果论文Agent-Pro:Learning to Evolve via Policy-level Reflection and Optimization被自然语言处理领域旗舰国际会议ACL 2024接收。论文共同一作为联培生汤柯,三作为联培生吴海,通信作者为李鹏副研究员。
目前,LLM Agent大多专注于特定任务。大部分LLM Agent缺乏从任务环境中学习的能力,他们无法通过与环境互动来提升自己的行为,从而更好地达成人类设定的目标。因此当面对复杂的动态的环境时,例如多人德州扑克、21点等大型非完美信息博弈游戏,LLM Agent给出的决策往往不够合理,不懂变通。那么,在不调整模型参数的前提下,LLM Agent能否像人类一样,在复杂动态环境中学习并持续提升,从一个新手小白进化为一个熟练的专家呢?
针对这一问题,团队开发了一种能够在交互环境中学习任务世界模型,优化自身行为策略的LLM-based Agent:Agent-Pro,从而具备在复杂动态的环境中学习与进化的能力。Agent-Pro以LLM作为基座模型,通过自我优化的Prompt来建模游戏世界模型和行为策略。Agent-Pro 动态地生成自我信念和对外部世界的信念,每次决策都基于这些信念,并动态地更新这些信念。Agent-Pro内部包括一个对任务世界的建模以及对自己行为策略的描述,在持续环境交互和探索中,Agent-Pro不断优化这个游戏世界模型和行为策略。通过对历史行动轨迹、信念和每局游戏结果进行策略级的反思,Agent-Pro“微调”其不正确的信念,优化一个更好的 prompt实现来对游戏世界和行为策略进行建模。
团队在多人德州扑克和21 点这两个广为流行的博弈游戏中进行了实验。结果表明,受益于持续优化的世界模型和行为策略,Agent-Pro的游戏水平不断提升,涌现出很多类似人类的高阶技巧: 虚张声势,欺诈,主动放弃等。在21点游戏上,Agent-Pro在大多数LLMs中显著超过了Vanilla LLM和其他的 Agents。在更为复杂的德州扑克游戏中,Agent-Pro不仅超过了基于LLM的基线代理,还击败了训练后的强化学习Agent,例如DMC。
在现实世界的情景中,如竞争、公司谈判和安全等,大多可以抽象为multi-agent博弈任务。Agent-Pro通过对这类情境的研究,为解决众多现实世界的问题提供了有效策略。
本项工作获得南京市重大科技专项(综合类)多模态智能协作机器人关键技术与系统项目资助。
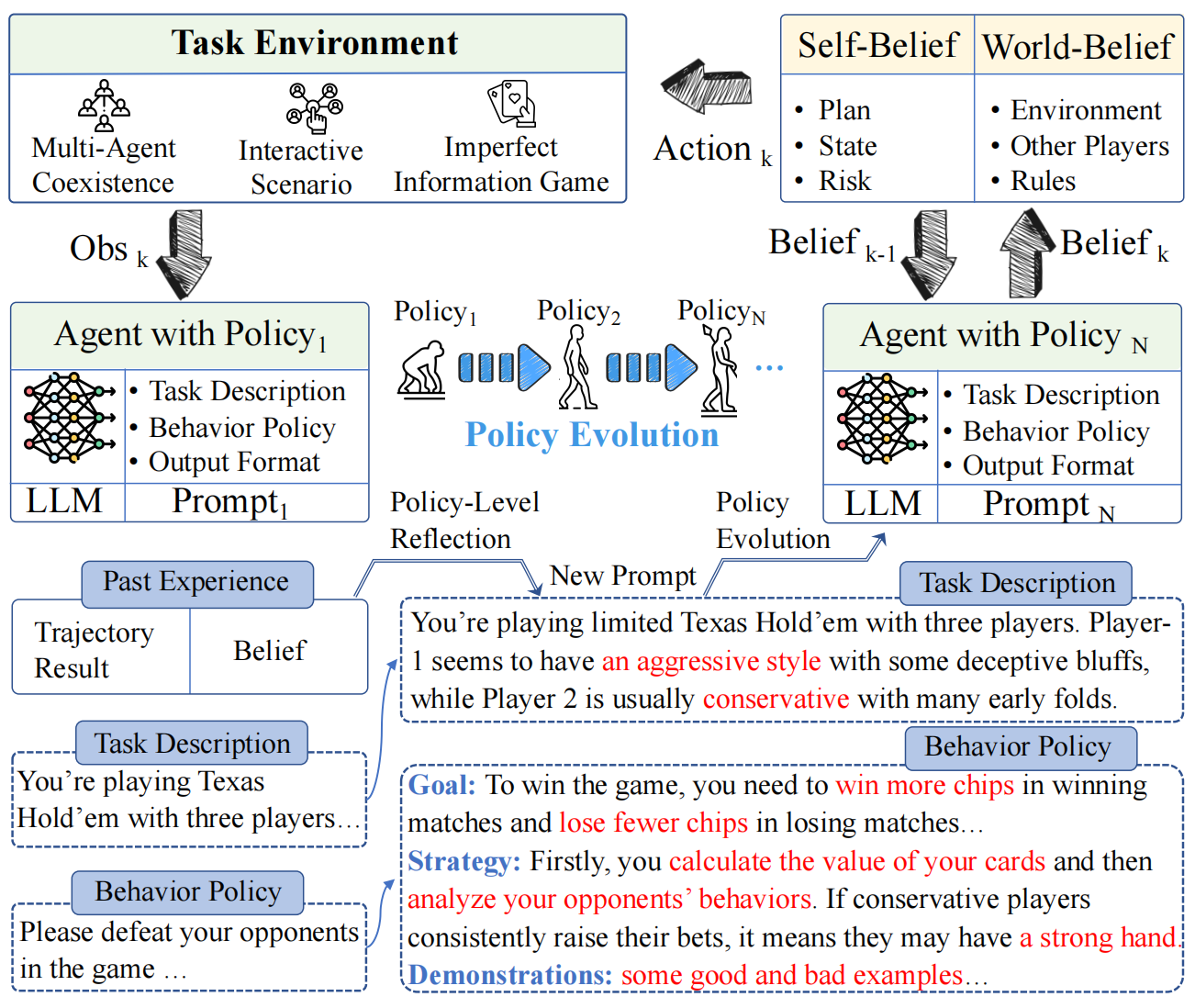
图1 Agent-Pro示意
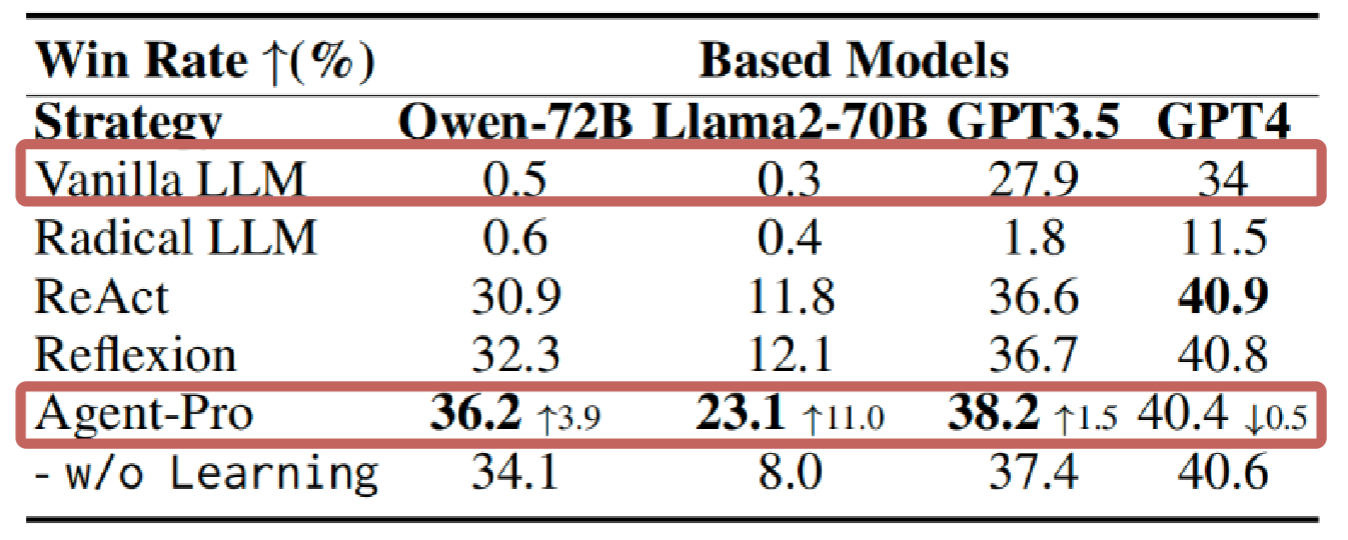
图2 21点实验结果
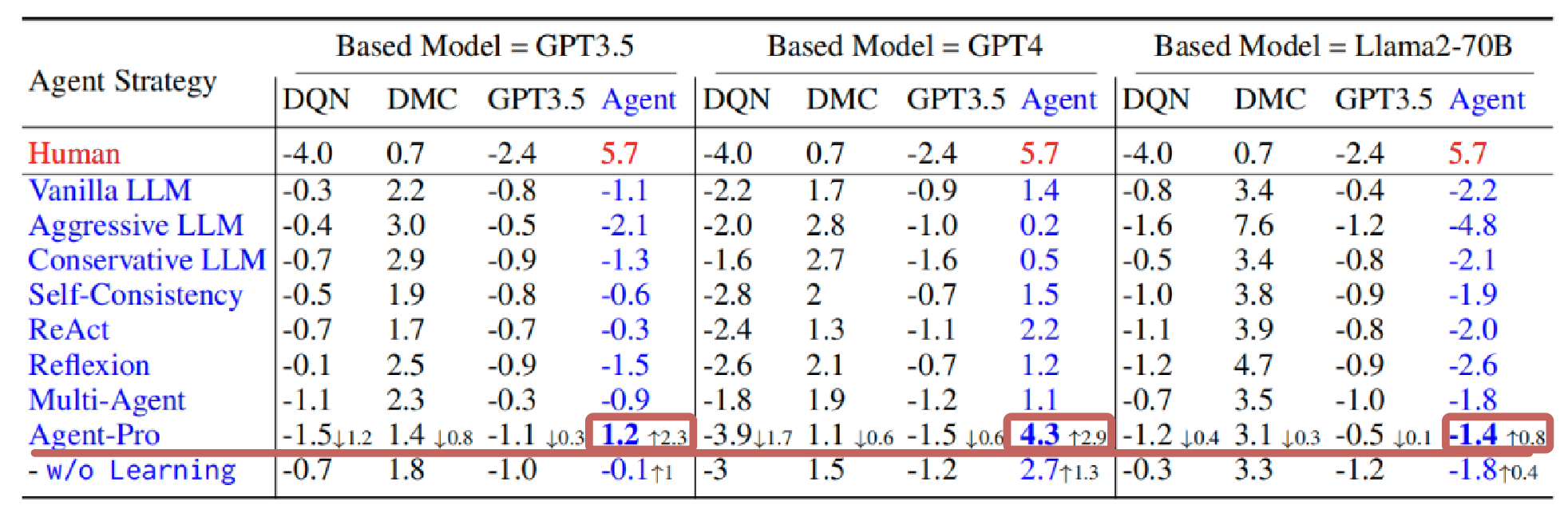
图3 德州扑克实验结果,分别以4个玩家为一组进行对弈,第4位置为测试Agent